はじめよう! (IntelliJ IDEA)¶
目次
IntelliJ IDEA のインストール¶
IntelliJ IDEA Community Edition をインストールしてください。
注釈
このドキュメントでは、IDE として IntelliJ IDEA Community Edition を用います。 IntelliJ IDEA Ultimate Edition を利用する場合は、 IntelliJ Doma support plugin の併用をお奨めします。
雛形プロジェクトのインポート¶
GitHub から simple-boilerplate を clone してください。
$ git clone https://github.com/domaframework/simple-boilerplate.git
IntelliJ IDEA を起動して Import Project を実行し、clone した simple-boilerplate を選択します。

Import project from external model をチェックし、Gradle を選択します。
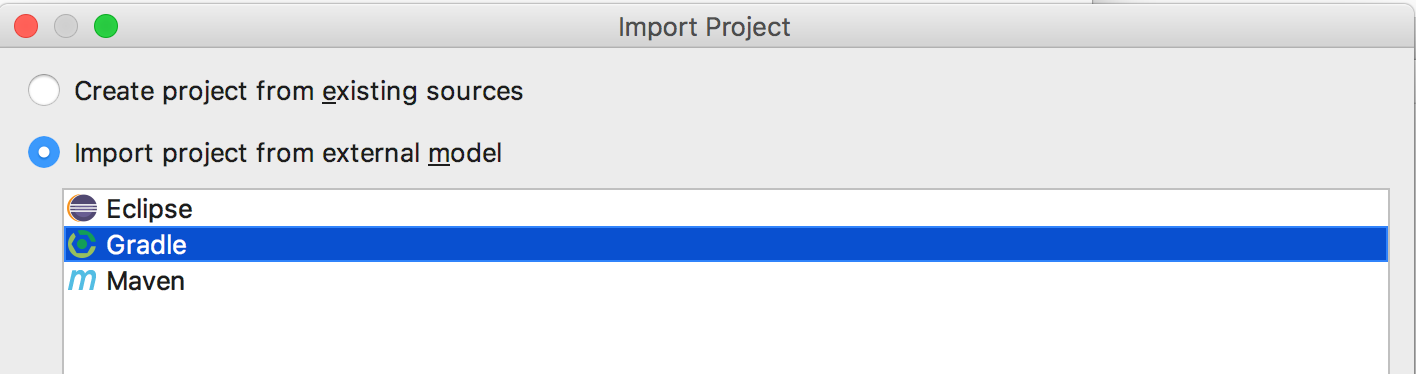
Use auto import をチェックし、 Create separate module per source set のチェックを外します。最後に Finish を押してください。
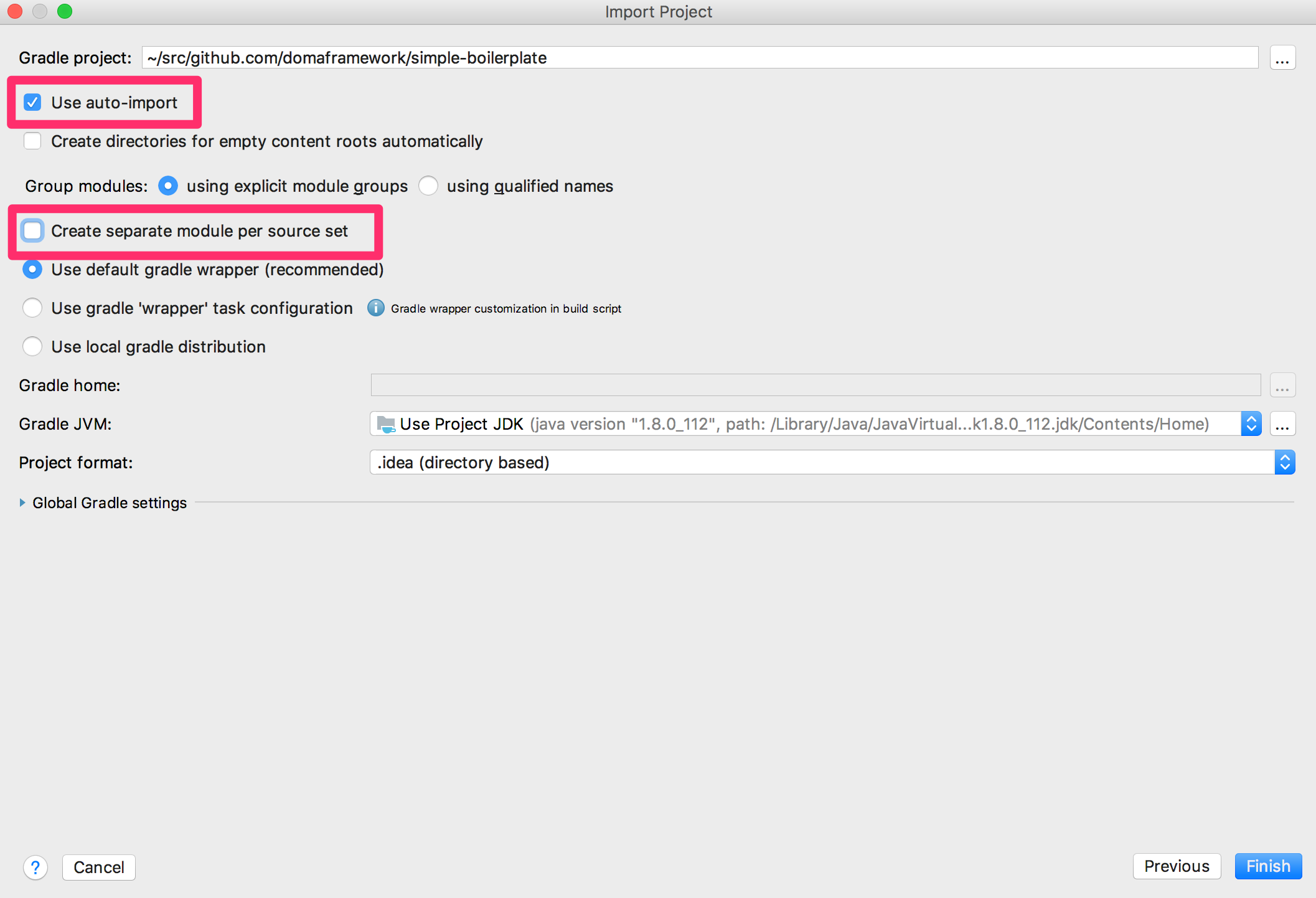
Build ツールウィンドウに synced successfully というメッセージが表示されればインポートは成功です。
Annotation Processor に関する設定¶
Project ツールウィンドウのコンテキストメニューから Open Module Settings を選択します。
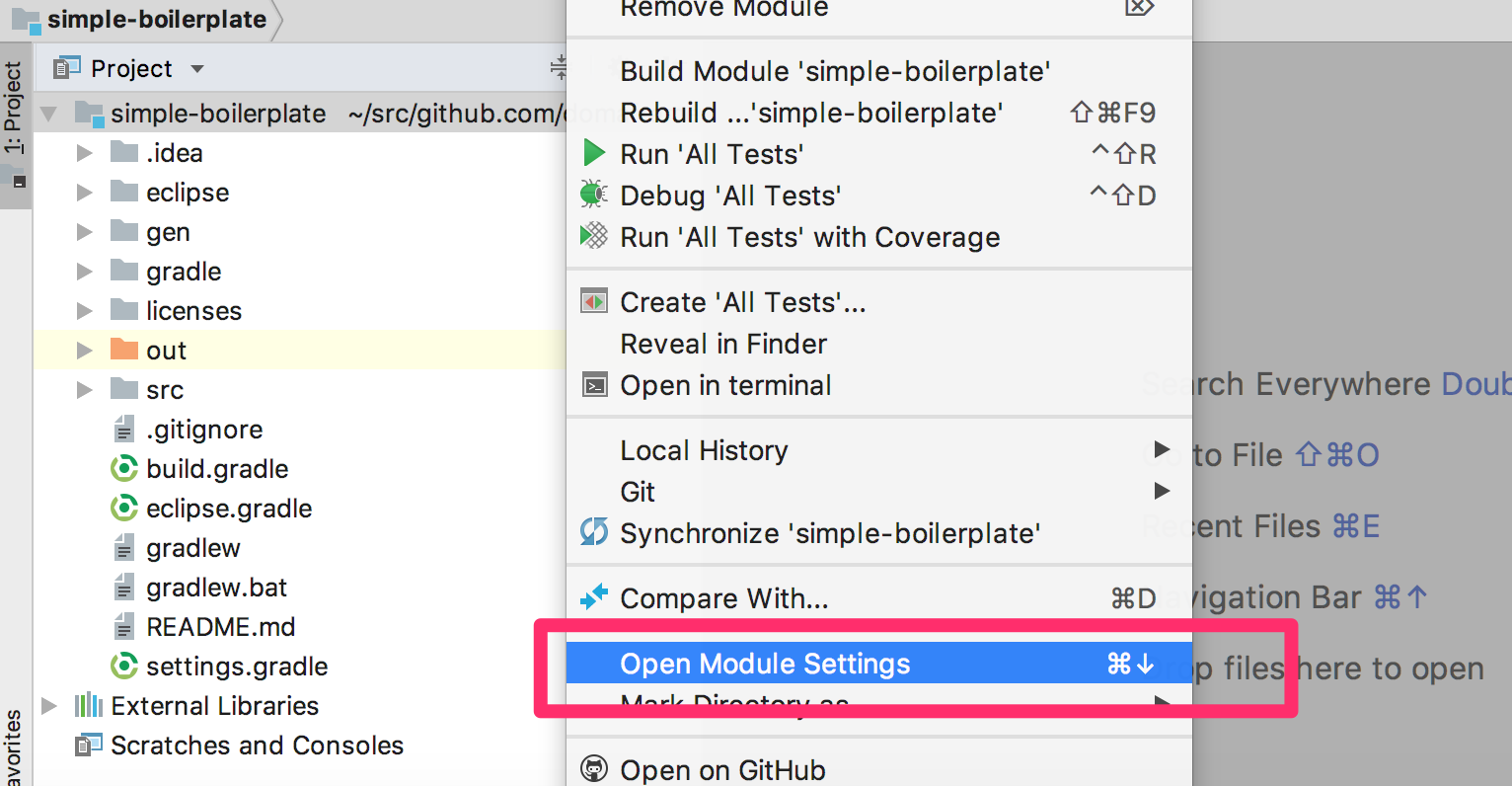
Modules の Paths の設定画面を開き、Inherit project compile output path が選択されていることを確認してください。 選択されていない場合は選択してください。
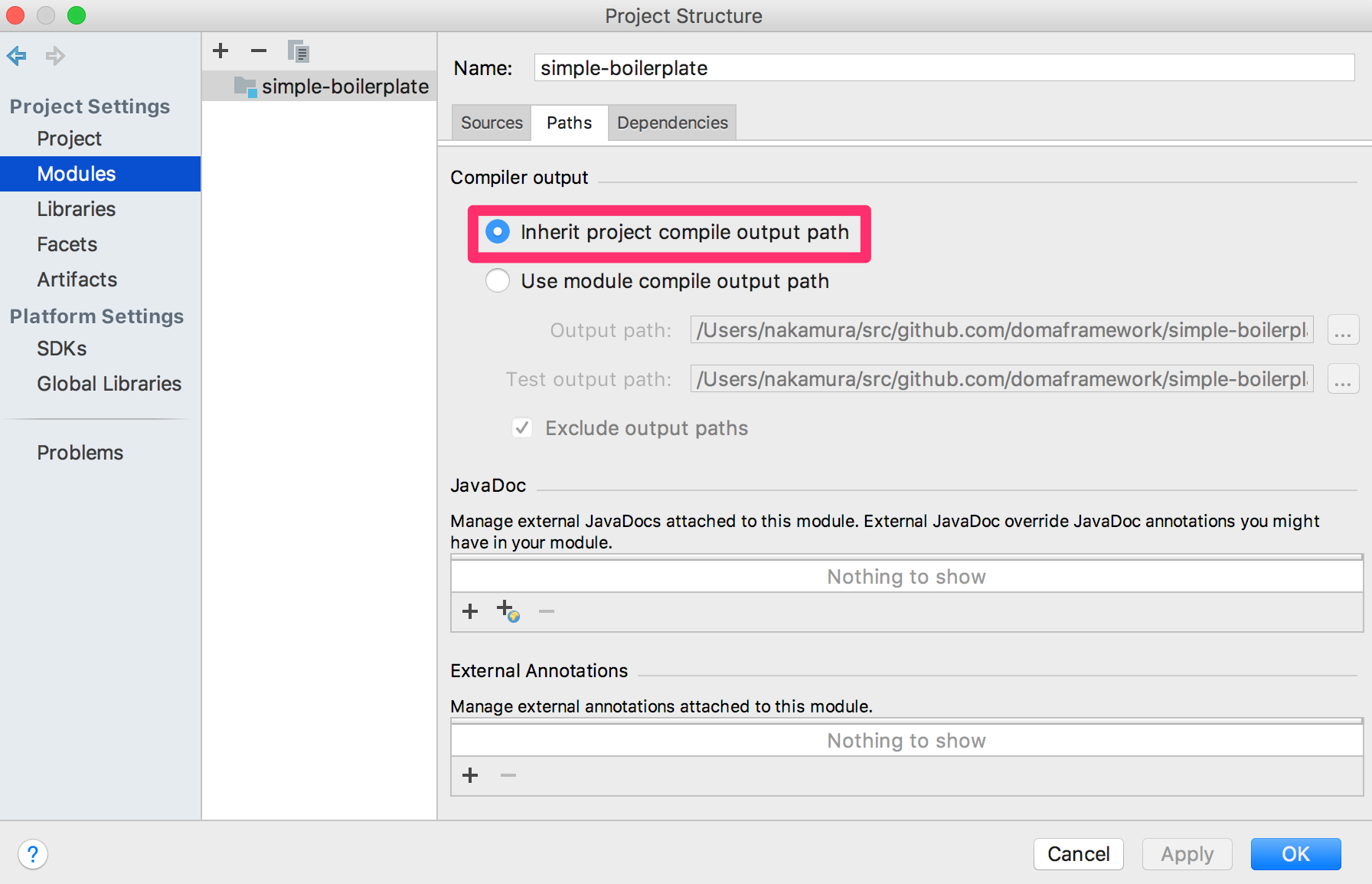
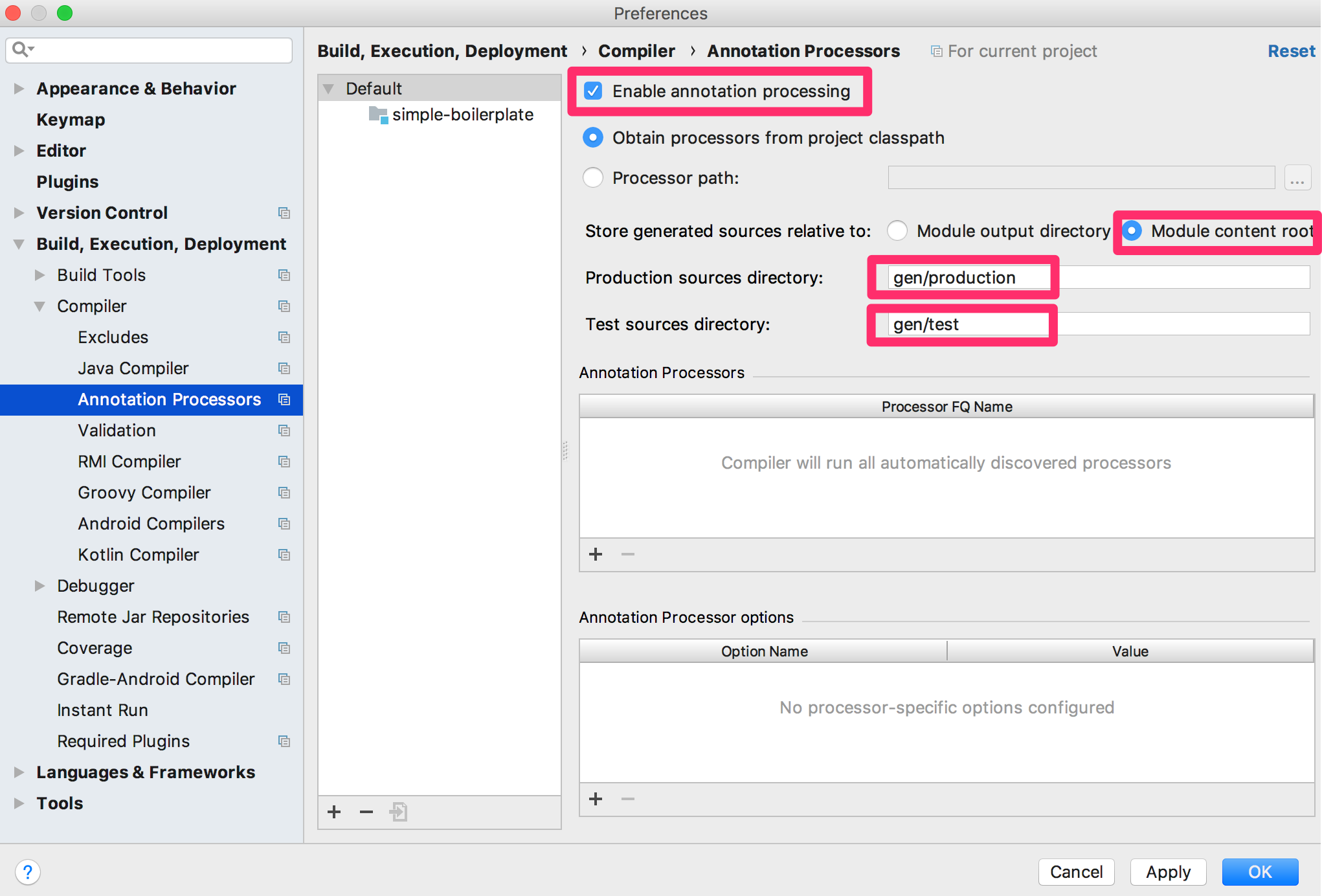
Preferrences から Build, Execution, Deployment > Compiler > Annotation Processors を開きます。 Enable annotation processing をチェックしてください。 Module content root をチェックしてください。 Production sources directory には gen/production 、Test sources directory には gen/test と入力してください。 最後に OK を押してください。
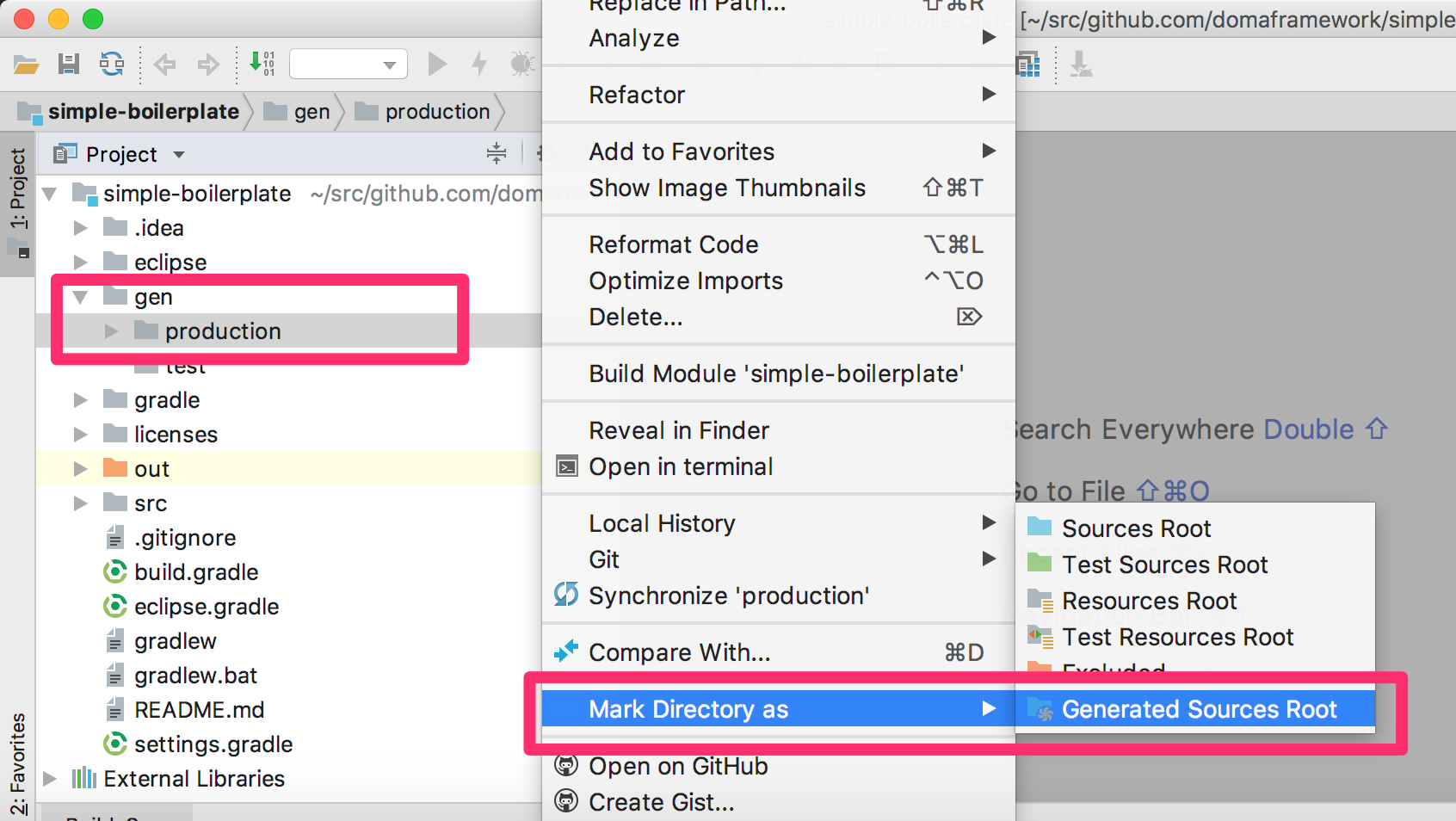
メニューから Build Project を実行してください。 ビルドにより Annotation Processor により生成されたコードが gen/production に出力されます。 Project ツールウィンドウのコンテキストメニューから Mark Directory as | Generated Sources Root を選択し、 gen/production をソースパスに追加します。
雛形プロジェクトの構成¶
プロジェクトのソースコードの構成は次のようになっています。
─ src
├── main
│ ├── java
│ │ └── boilerplate
│ │ ├── AppConfig.java
│ │ ├── dao
│ │ │ ├── AppDao.java
│ │ │ └── EmployeeDao.java
│ │ └── entity
│ │ └── Employee.java
│ └── resources
│ └── META-INF
│ └── boilerplate
│ └── dao
│ ├── AppDao
│ │ ├── create.script
│ │ └── drop.script
│ └── EmployeeDao
│ ├── selectAll.sql
│ └── selectById.sql
└── test
├── java
│ └── boilerplate
│ ├── DbResource.java
│ └── dao
│ └── EmployeeDaoTest.java
└── resources
主要なものについて説明します。
- AppConfig.java
- Doma を実行するために必要な 設定 です。
- AppDao.java
- このアプリケーションで利用するデータベースのスキーマを実行時に作成/破棄するユーティリティです。
実環境では不要になります。
スキーマの作成と破棄には
META-INF/boilerplate/dao/AppDao/以下のスクリプトファイルを使用します。 - Employee.java
- データベースの EMPLOYEE テーブルに対応する Entity classes です。
- EmployeeDao.java
Employeeクラスの取得や更新などを行う Dao interfaces です。META-INF/boilerplate/dao/EmployeeDao/以下の SQLファイル を使用します。- EmployeeDaoTest.java
EmployeeDaoを使ったテストです。 このファイルにテストケースを追加しながら Doma の学習ができます。 テストメソッドごとにデータベーススキーマの作成と破棄を行っているため データの更新によって他のテストが影響を受けることはありません。
SQL ファイル¶
META-INF/boilerplate/dao/EmployeeDao/selectById.sql ファイルを開いてください。
このファイルには次のように記述されています。
select
/*%expand*/*
from
employee
where
id = /* id */0
/*%expand*/ は Java メソッドでマッッピングされた
エンティティクラスの定義を参照してカラムリストを展開することを示しています。
/* id */ は Java メソッドのパラメータの値がこの SQL へバインドされることを
示しています。
後ろにある 0 はテスト用のデータです。
このテストデータを含めることで、 SQL をツールで実行して構文上の
誤りがないことを容易に確認できます。
テスト用のデータは Java プログラム実行時には使われません。
詳細については、 SQL を参照してください。
検索¶
Search 処理を実行するには、 @Select が注釈された Dao メソッドを呼び出します。
検索処理の追加¶
ある年齢より小さい従業員を検索する処理を追加する手順を示します。
EmployeeDao に次のコードを追加し、ビルドを実行してください。
@Select
List<Employee> selectByAge(Integer age);
このとき、注釈処理により次のエラーメッセージが Message ツールウィンドウ に表示されます。
[DOMA4019] ファイル[META-INF/boilerplate/dao/EmployeeDao/selectByAge.sql]が
クラスパスから見つかりませんでした。
src/main/resources/META-INF/boilerplate/dao/EmployeeDao の直下に
selectByAge.sql という名前のファイルを作成し、ファイルは空のままにして再度ビルドしてください。
エラーメッセージの内容が変わります。
[DOMA4020] SQLファイル[META-INF/boilerplate/dao/EmployeeDao/selectByAge.sql]が空です。
selectByAge.sql ファイルに戻って次の SQL を記述してください。
select
/*%expand*/*
from
employee
where
age < /* age */0
再度ビルドをするとエラーが解消されます。
検索処理の実行¶
上記で作成した検索処理を実際に実行します。
EmployeeDaoTest に次のコードを追加してください。
@Test
public void testSelectByAge() {
TransactionManager tm = AppConfig.singleton().getTransactionManager();
tm.required(() -> {
List<Employee> employees = dao.selectByAge(35);
assertEquals(2, employees.size());
});
}
JUnit を実行し、このコードが動作することを確認してください。
このとき発行される検索のための SQL は次のものです。
select
age, id, name, version
from
employee
where
age < 35
挿入¶
Insert 処理を実行するには、 @Insert が注釈された Dao メソッドを呼び出します。
挿入処理の実行¶
EmployeeDao に次のコードが存在することを確認してください。
@Insert
int insert(Employee employee);
このコードを利用して挿入処理を実行します。
EmployeeDaoTest に次のコードを追加してください。
@Test
public void testInsert() {
TransactionManager tm = AppConfig.singleton().getTransactionManager();
Employee employee = new Employee();
// 最初のトランザクション
// 挿入を実行している
tm.required(() -> {
employee.name = "HOGE";
employee.age = 20;
dao.insert(employee);
assertNotNull(employee.id);
});
// 2番目のトランザクション
// 挿入が成功していることを確認している
tm.required(() -> {
Employee employee2 = dao.selectById(employee.id);
assertEquals("HOGE", employee2.name);
assertEquals(Integer.valueOf(20), employee2.age);
assertEquals(Integer.valueOf(1), employee2.version);
});
}
JUnit を実行し、このコードが動作することを確認してください。
このとき発行される挿入のための SQL は次のものです。
insert into Employee (age, id, name, version) values (20, 100, 'HOGE', 1)
識別子とバージョン番号が自動で設定されています。
更新¶
Update 処理を実行するには、 @Update が注釈された Dao メソッドを呼び出します。
更新処理の実行¶
EmployeeDao に次のコードが存在することを確認してください。
@Update
int update(Employee employee);
このコードを利用して更新処理を実行します。
EmployeeDaoTest に次のコードを追加してください。
@Test
public void testUpdate() {
TransactionManager tm = AppConfig.singleton().getTransactionManager();
// 最初のトランザクション
// 検索して age フィールドを更新している
tm.required(() -> {
Employee employee = dao.selectById(1);
assertEquals("ALLEN", employee.name);
assertEquals(Integer.valueOf(30), employee.age);
assertEquals(Integer.valueOf(0), employee.version);
employee.age = 50;
dao.update(employee);
assertEquals(Integer.valueOf(1), employee.version);
});
// 2番目のトランザクション
// 更新が成功していることを確認している
tm.required(() -> {
Employee employee = dao.selectById(1);
assertEquals("ALLEN", employee.name);
assertEquals(Integer.valueOf(50), employee.age);
assertEquals(Integer.valueOf(1), employee.version);
});
}
JUnit を実行し、このコードが動作することを確認してください。
このとき発行される更新のための SQL は次のものです。
update Employee set age = 50, name = 'ALLEN', version = 0 + 1 where id = 1 and version = 0
楽観的排他制御のためのバージョン番号が自動でインクリメントされています。
削除¶
Delete 処理を実行するには、 @Delete が注釈された Dao メソッドを呼び出します。
削除処理の実行¶
EmployeeDao に次のコードが存在することを確認してください。
@Delete
int delete(Employee employee);
このコードを利用して削除処理を実行します。
EmployeeDaoTest に次のコードを追加してください。
@Test
public void testDelete() {
TransactionManager tm = AppConfig.singleton().getTransactionManager();
// 最初のトランザクション
// 削除を実行している
tm.required(() -> {
Employee employee = dao.selectById(1);
dao.delete(employee);
});
// 2番目のトランザクション
// 削除が成功していることを確認している
tm.required(() -> {
Employee employee = dao.selectById(1);
assertNull(employee);
});
}
JUnit を実行し、このコードが動作することを確認してください。
このとき発行される削除のための SQL は次のものです。
delete from Employee where id = 1 and version = 0
識別子に加えバージョン番号も検索条件に指定されます。